Refund Abuse Detection System — RAD
The problem
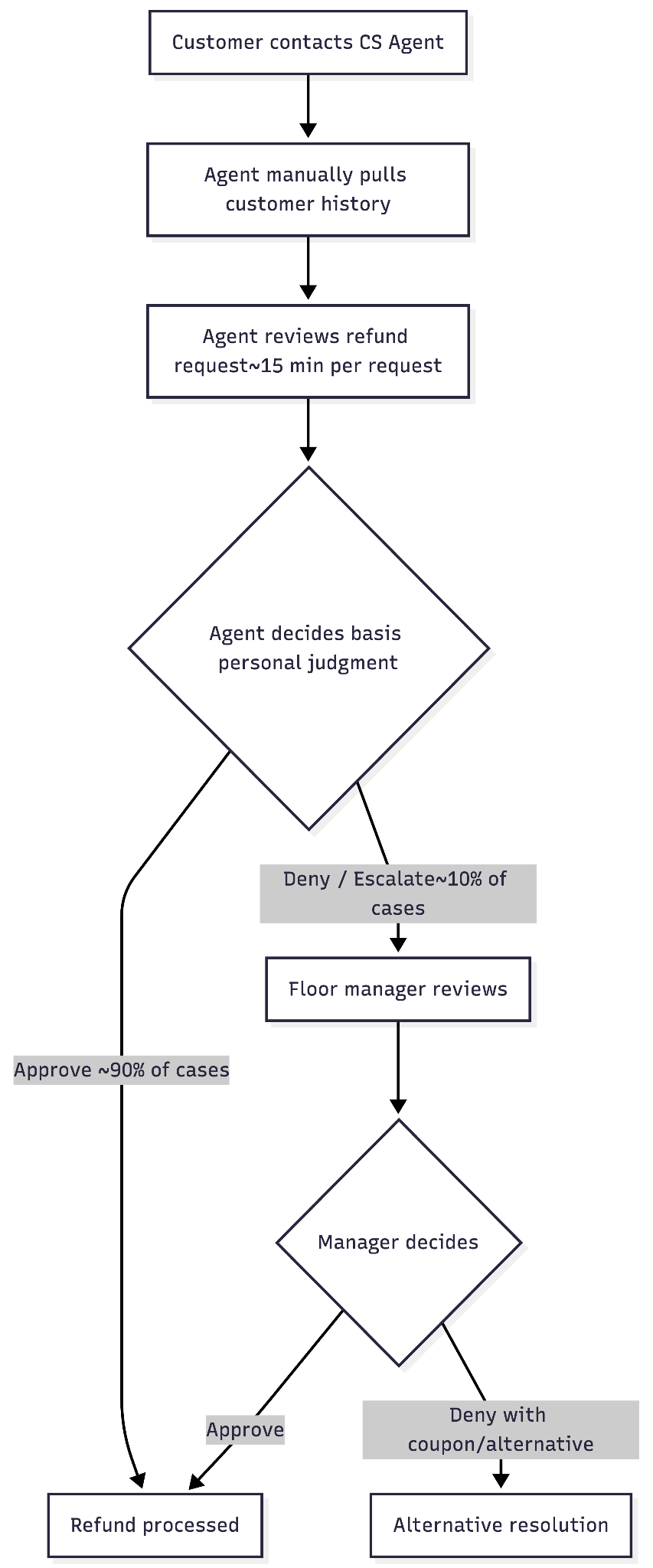
Horizon† processes over 5,000 refund requests every month. Each one is handled manually by a customer service agent. At roughly 15 minutes per request, that is 1,250 agent hours a month — spent entirely on review, judgment, and resolution.
The approval rate sits at 90%. That is not negligence. It is rational. Agents have no objective information basis to do anything else. They operate on personal judgment, and when judgment is the only tool, the safest call is usually to approve. The cost of a wrongful denial — a complaint, a chargeback, a negative review — is immediate and visible. The cost of an approved fraudulent refund is deferred, diffuse, and usually invisible until an audit 15 days later. By then the refund has already been processed and there is no mechanism to course-correct.
An estimated 5% of requests — around 250 per month — exhibit patterns that suggest abuse. These do not always surface at the individual interaction level. Some only become visible in retrospective analysis, when it is too late. And because there is no shared policy framework, two agents can receive identical requests and reach different outcomes. One flags a repeat refunder. The other approves without a second thought. The inconsistency is a natural consequence of the process design, not a failure of individual agents.
5,000 refunds/month × 15 min = 1,250 agent hours/month. At a conservative $5/hour agent cost, that is $6,250/month in processing time — before counting financial leakage from approved fraudulent refunds. The system described here costs ~$78/month to run.
Who's involved
Before designing anything, I mapped the full range of people the system would interact with — both the customers making refund claims and the operators processing them. The customer personas matter because the same claim can come from very different places, and the engagement style influences agent perception even when the underlying facts are identical. That inconsistency is one of the core problems.
Customer personas
-
Legitimate Customer. The baseline against which everything else is measured. Four sub-types: no-show within eligible policy, cancellation within window, partial service failure (not all components delivered), systemic no-show (venue-side failure). Each has a different evidence profile and a different correct resolution. The system must distinguish all of them from each other and from abuse.
-
Chancer. Engaged with the experience, enjoyed it, takes a shot at a refund anyway. The interesting dimension here is the engagement style: a one-off polite claim looks different from an adamant insistence despite QR evidence of attendance. Both are the same behaviour, but the agent's perception differs. This is exactly where objectivity matters — the system surfaces the QR contradiction regardless of how the customer is presenting.
-
Arbitrageur. Speculates on high-value bookings — purchases in advance, sometimes across multiple accounts, hoards them to resell informally. The primary signal is the gap between booking volume and actual attendance. Multiple cancellations on high-value experiences is the pattern. Distinct from the Coordinator by intent, though their engagement can look similar from the outside.
-
Coordinator. One or more persons booking across multiple accounts, getting experiences at a fraction of cost via systematic refunds. Requires network and graph analysis to identify definitively — shared devices, payment methods, overlapping booking metadata. That infrastructure is out of scope for the initial build. Layer 0 catches the symptom (unusual refund clustering on a single experience/date) even if it cannot identify the network. Coordinator-level detection is explicitly flagged as a known gap for a future workstream.
Operator personas
-
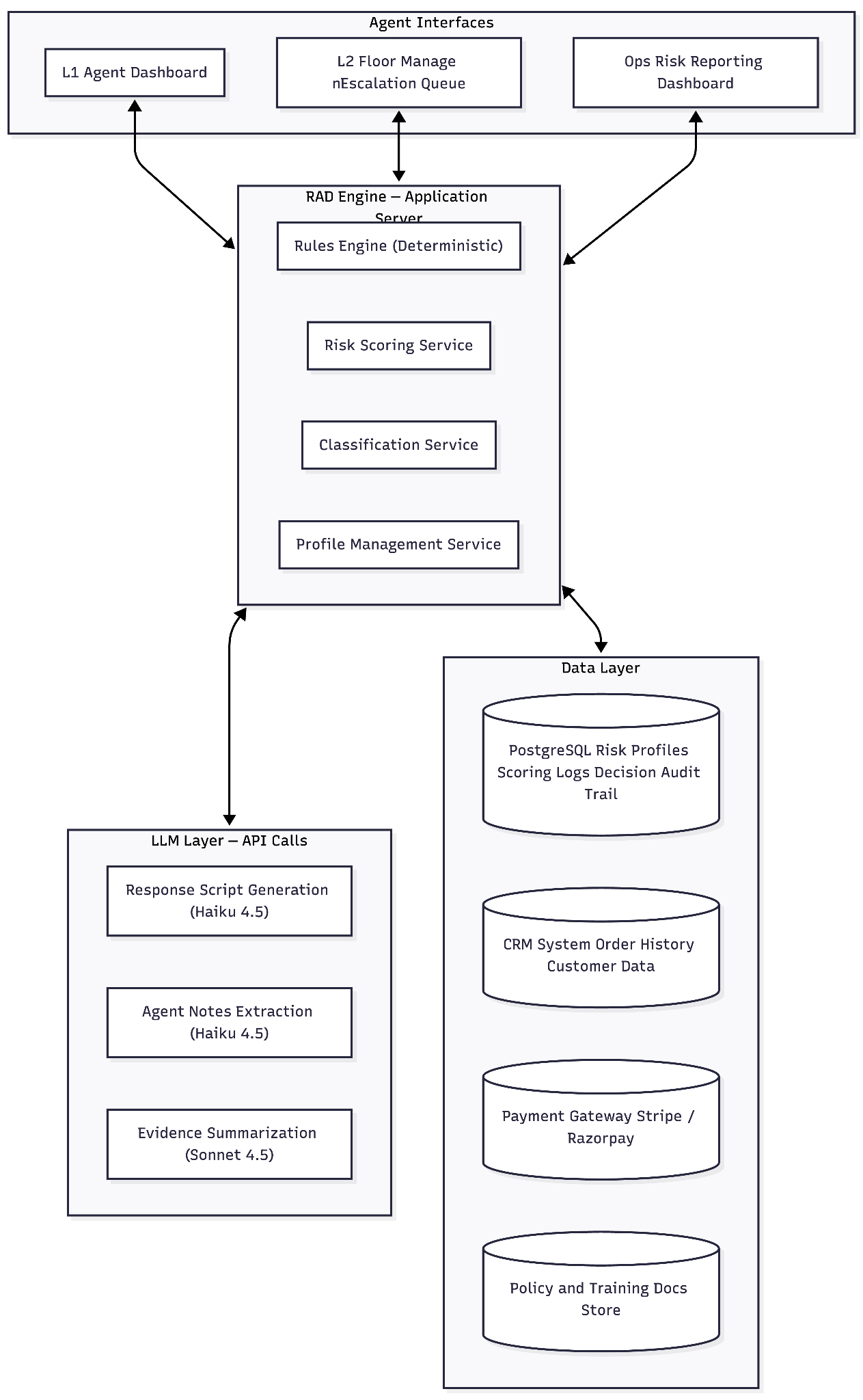
L1 Support (Customer Service Agent). The primary user. Needs real-time, evidence-backed decision support surfaced before they even ask for a refund. Retains full override authority — overrides are logged with a reason, but the system never removes the agent's ability to decide. The interface must not slow them down; it should load while they are greeting the customer.
-
L2 Support (Floor Manager). Handles escalated cases. Needs the complete evidence packet with source-data drill-down — from any flag to the specific booking record or QR log that generated it. Has authority to approve, deny, or offer alternatives. Every L2 decision is logged with reasoning.
-
Operations / Risk Team. Not a real-time user. Consumes aggregate dashboards: fraud loss rate, auto-approval rates, false positive rates, override tracking, supplier anomaly trends. Generates supplier-facing reports when experience-level patterns point to vendor-side issues.
Design principles and non-goals
- Human in the loop. The system recommends; humans decide. For anything beyond the auto-approval threshold, an agent or floor manager makes the final call. The system never auto-denies.
- Explainability. Every flag, score, and recommendation must be traceable to specific data points. A conclusion that cannot be walked back to its source is not acceptable — for L2 audit, for ops review, and for agent trust in the system.
- Preserve the legitimate customer experience. The system should make life faster for good customers through auto-approval, not slower. Friction for legitimate customers is a failure mode, not an acceptable trade-off.
- Objectivity over discretion. Identical requests should produce consistent outcomes regardless of which agent handles them. Data grounds the decision; individual judgment is still in the loop, but as the final filter rather than the primary one.
- Responsive to the live conversation. After its initial assessment, the system remains available throughout the call. If the situation evolves — the customer becomes aggressive, provides new information, threatens a chargeback — the agent can relay that context and receive updated guidance grounded in policy.
- Enable future analytics. Every interaction, decision, and override is logged in structured form. This creates the data foundation for retrospective audits, supplier reporting, and eventually a supervised ML layer once labeled data accumulates.
Explicit non-goals: replacing humans entirely in the decision process; auto-denying refunds without explanation or human review; redesigning vendor refund policies (the system works within existing frameworks); coordinator-level network detection in the initial build.
Data and constraints
The system works with two categories of data, and is shaped by three hard constraints that determined the architecture before a line of design was written.
Confirmed available signals (6)
| Signal | What it captures |
|---|---|
| Refund history | Count and frequency of past refund requests |
| Refund timing | Days before or after the experience the refund was requested |
| Experience value | Percentile ranking of the booking within the full catalog |
| Customer tenure | Account age and engagement history |
| Email engagement | Whether booking confirmation and reminder emails were opened |
| No-show history | Instances where customer did not attend a booked experience |
CRM-enrichable signals (7)
The CRM system holds order history, which makes the following accessible: supplier type (direct contract vs. aggregator vs. last-minute marketplace), confirmation TAT (promised vs. actual delivery time), booking confirmation delivery status, inventory type, QR scan and check-in logs, self-service cancellation history, and agent notes from prior interactions.
The confirmation TAT signal deserves specific attention. If the system can verify that a booking confirmation was delivered at 10:14 AM and the customer opened it at 10:22 AM, a subsequent "never received confirmation" claim is directly contradicted by evidence. Conversely, if confirmation was never sent, or was sent six hours late on a product that promised a two-hour window, the refund claim is almost certainly legitimate regardless of the customer's risk profile. The same data point can exonerate or indict, which makes it among the most powerful available signals.
Three constraints that shaped the architecture
- QR data is inconsistent. Vendor check-in reports vary in frequency and reliability. The system cannot require QR data as an input — it must function without it and treat QR confirmation as a high-confidence bonus when present. When QR data is unavailable, the evidence card explicitly notes the thinner basis.
- No labeled fraud data exists. Only retrospective flags of users identified as abusive after the fact, discovered inconsistently during audits. This rules out supervised ML at launch. The system must be entirely deterministic and rules-based. Retrospective flags serve as the calibration set for threshold-setting, not training data.
- Refund policy varies by product type. Cancelable products get 100% refunds within the applicable window. Some products have vendor-negotiated flexibility at 50% or 25%. Non-cancelable products go to floor manager discretion. The system must know which policy applies before evaluating abuse potential — a refund that is contractually owed is not abuse regardless of the customer's risk score.
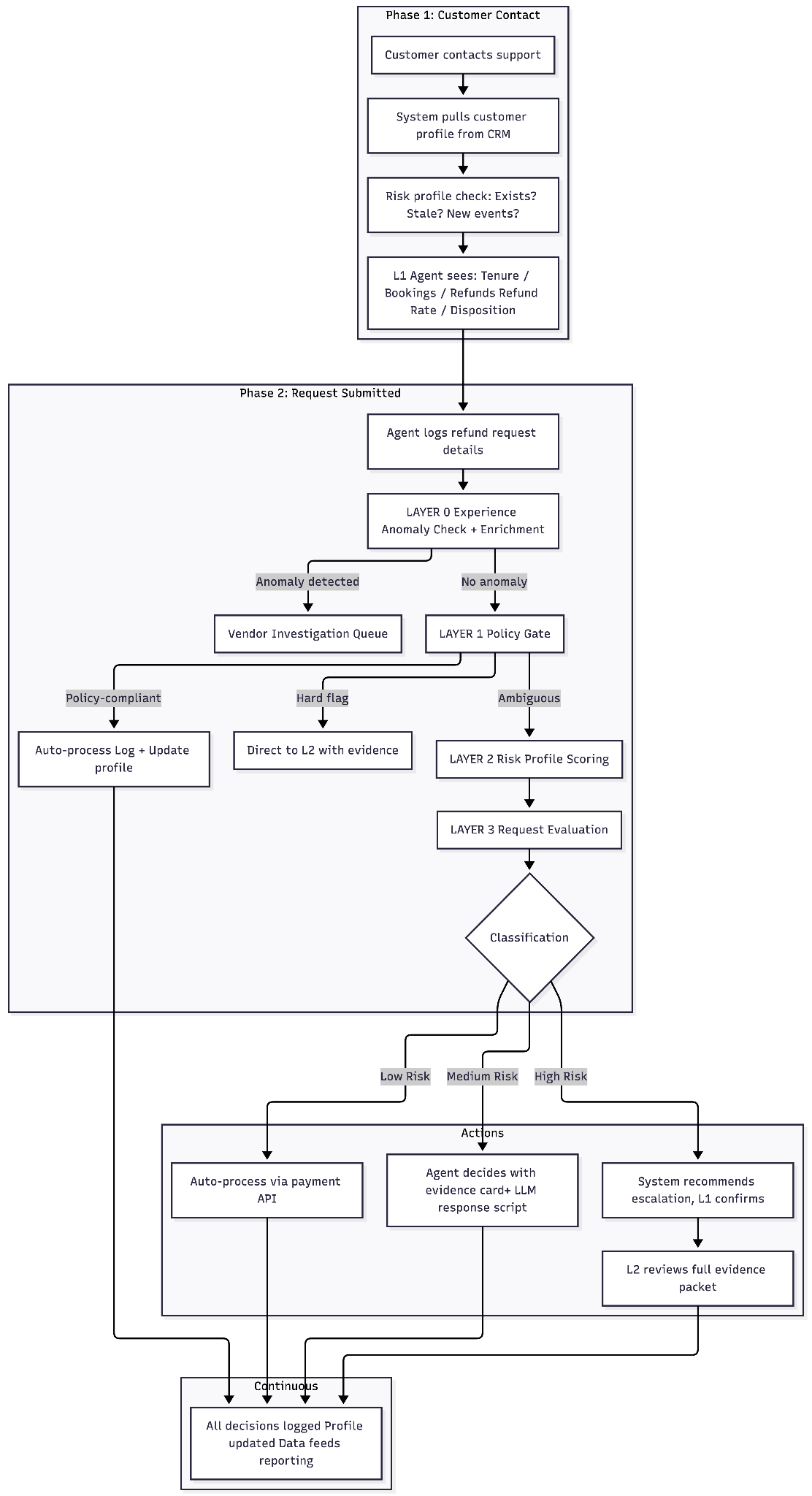
How it works — six layers
The system evaluates each refund request through a sequential layered architecture. Each layer handles the cases it can definitively resolve before passing the rest to the next layer. The result is that the most common and clearest cases are resolved fastest, without consuming the scoring infrastructure unnecessarily.
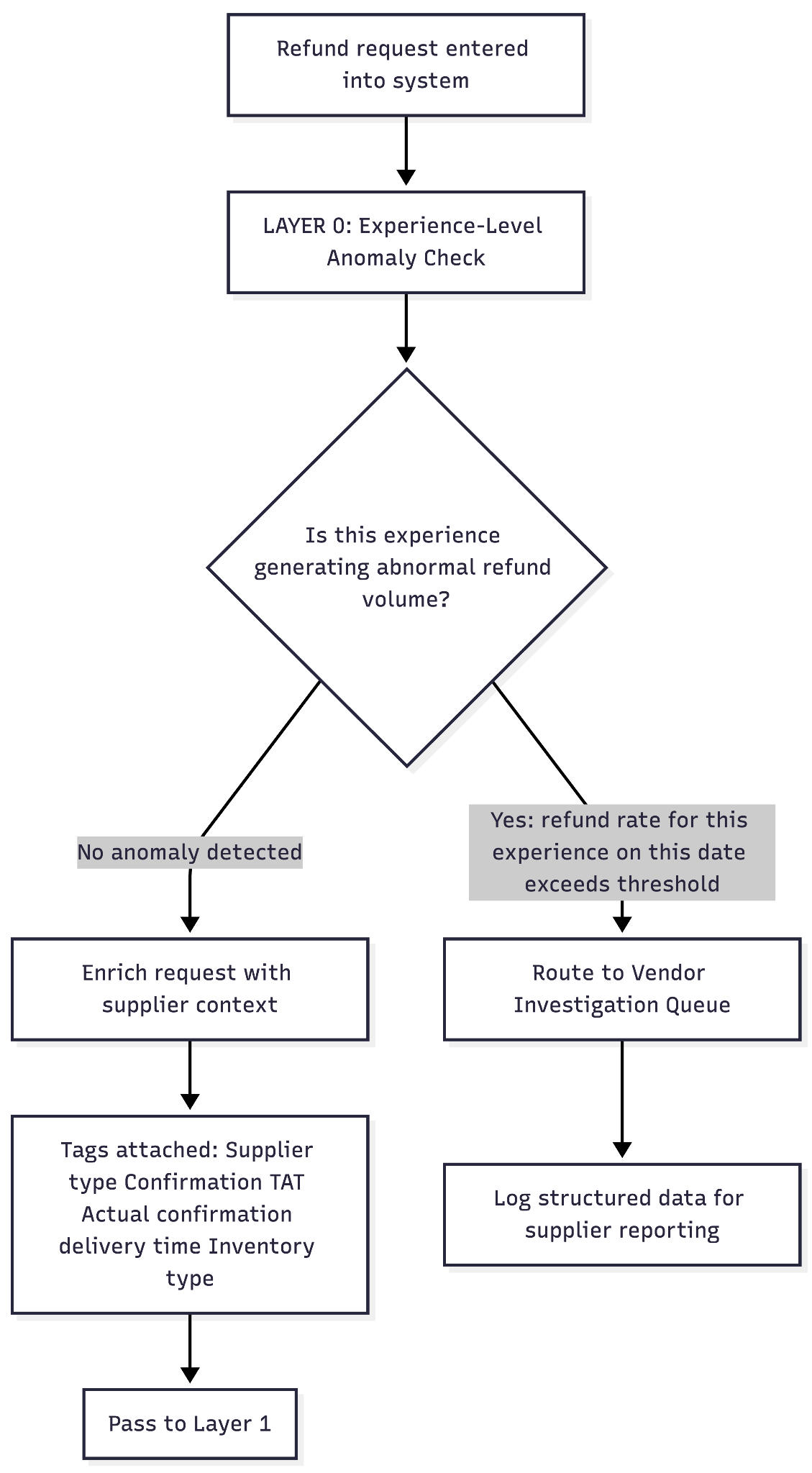
Layer 0 — Experience-level anomaly check
Before evaluating the individual customer at all, the system first asks: is this experience generating an abnormal volume of refund requests on this specific date?
This layer exists because when multiple customers file refund claims for the same experience on the same day, the root cause is far more likely to be a vendor or product failure — the tour guide did not show up, a weather cancellation, an operational issue — than individual customer abuse. Without this check, the system would flag 20 legitimate customers as suspicious simply because a vendor failed to deliver. Any threshold triggering (default: 3× the average refund rate for that experience category) routes all related requests to a Vendor Investigation Queue, bypassing the abuse-detection path entirely.
Regardless of whether an anomaly is detected, the layer enriches every request with supplier context. This enrichment travels with the request through all subsequent layers.
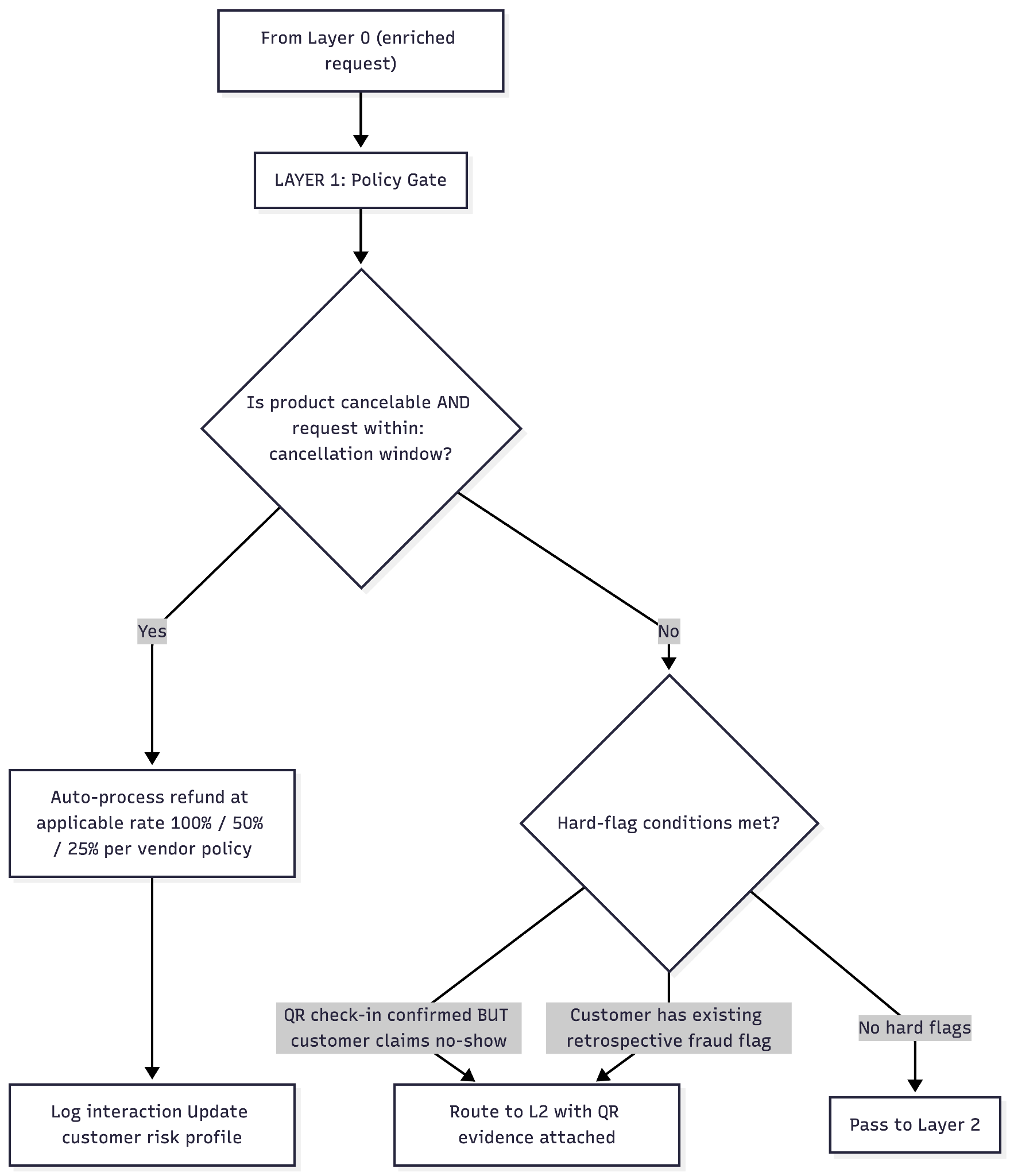
Layer 1 — Policy gate
A deterministic binary gate. The question it answers: does the existing refund policy already dictate the outcome of this request?
If yes, the refund is processed without scoring the customer. This is a deliberate design choice. A cancellation within the applicable window is a contractual right offered at the time of purchase. Blocking it based on a risk score creates legal exposure and is fundamentally unfair. The system treats policy compliance as a hard override.
The key nuance: even auto-processed requests update the customer's risk profile. A customer who books and cancels within the cancellation window repeatedly is exhibiting the arbitrageur pattern. The flag is not "deny this refund" — it is "this customer's booking-to-cancellation ratio is unusual; watch for escalation on future non-policy-compliant requests." Each compliant cancellation is processed correctly and accumulated as a data point.
Two conditions bypass scoring entirely and route straight to L2 with evidence attached: QR check-in confirms attendance but the customer claims no-show; or the customer has an existing retrospective fraud flag from a prior audit cycle. Everything else proceeds to Layer 2.
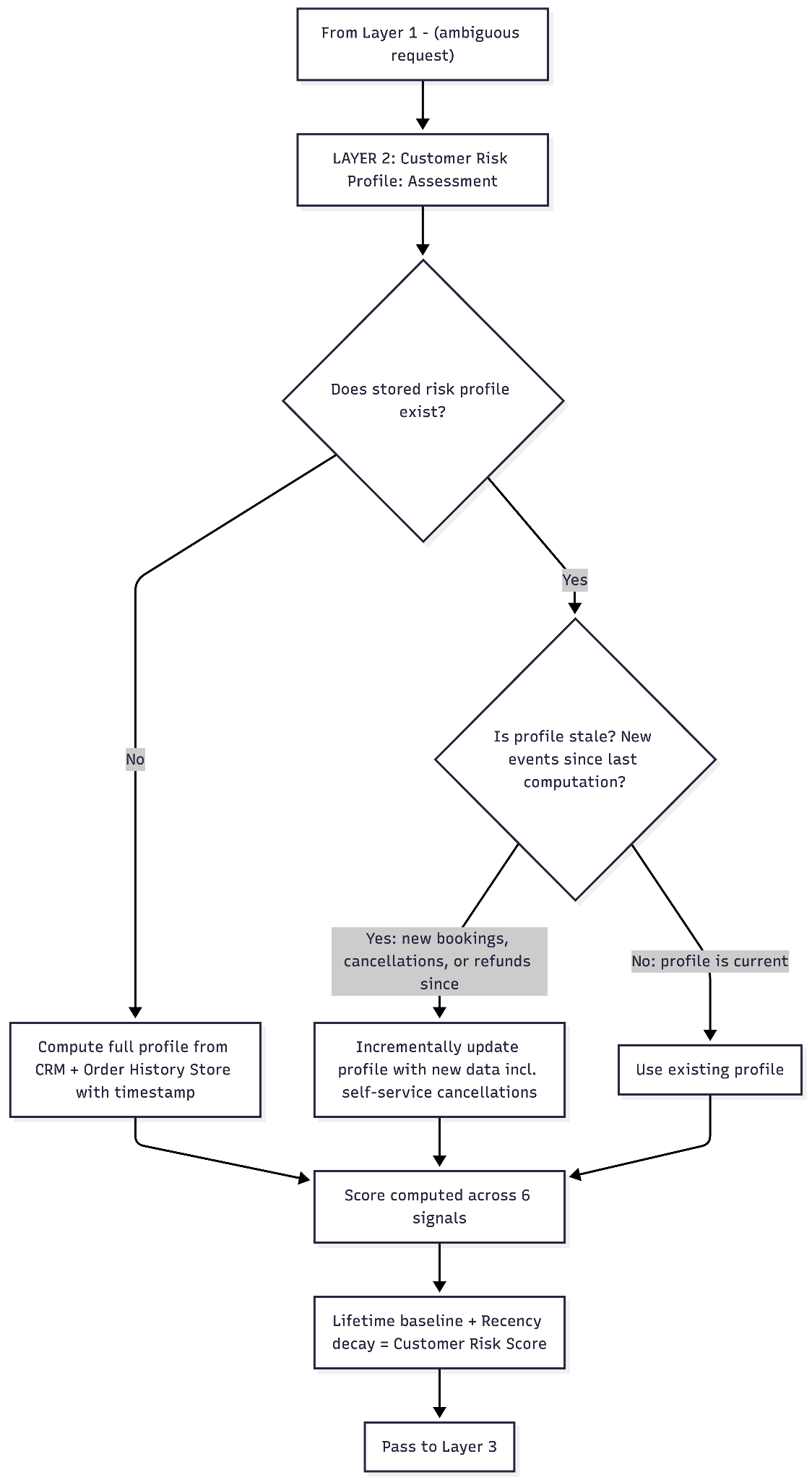
Layer 2 — Customer risk profile
This layer evaluates the customer's historical behavior. Six signals, computed across lifetime history with recency weighting.
The weighting rationale matters. Refund frequency and no-show history are weighted highest because they are behavioral patterns the customer directly controls and that are difficult to explain away at scale. Email engagement and timing are medium-weighted — contextual signals that are useful in aggregate but individually ambiguous. Experience value and tenure are modifiers: they do not indicate abuse on their own but change the significance of everything else.
| Signal | Weight | Key design decision |
|---|---|---|
| Refund frequency | High | Ratio, not raw count. 15 refunds from 16 bookings ≠ 15 refunds from 200 bookings. >40% refund-to-booking ratio is a significant positive risk signal. |
| No-show + refund claim history | High | Only the paired combination is scored — no-show alone is not a signal. QR-contradicted claims carry heavy weight. Prior approvals of contradicted claims still accumulate in the profile. |
| Email engagement | Medium | A soft signal. Plenty of people do not open confirmation emails legitimately. Meaningful in aggregate with other signals, never standalone. |
| Refund timing | Medium | Post-experience claims are inherently more suspicious than pre-experience. Last-minute requests on non-cancelable products carry moderate risk. |
| Experience value percentile | Low–medium | Amplifier. Abuse targeting high-value experiences is more costly per incident and more likely deliberate. Never drives a decision alone. |
| Customer tenure | Modifier | Provides the denominator. A 3-year customer with 50 completed bookings and one refund request is fundamentally different from a 2-month account with 4 bookings and 3 requests. |
One design choice worth explaining: why lifetime history and not a 6-month trailing window? A customer who was active January–June 2025, went dormant, and returns in February 2026 would show zero history in a trailing 6-month window. That is not the right conclusion — their prior behavior still carries predictive signal. The 6-month window from the problem statement becomes the high-weight zone within a decay function (full weight at 0–90 days, reduced at 90–180 days, minimal but non-zero beyond 180 days), not the only window.
The profile is stored with a timestamp and checked for staleness on each interaction. If new events have occurred since the last computation, the profile is incrementally updated. Every flag in the stored profile is traceable to specific source records — L2 can drill down from any flag to the underlying booking record, refund history entry, or QR log that generated it.
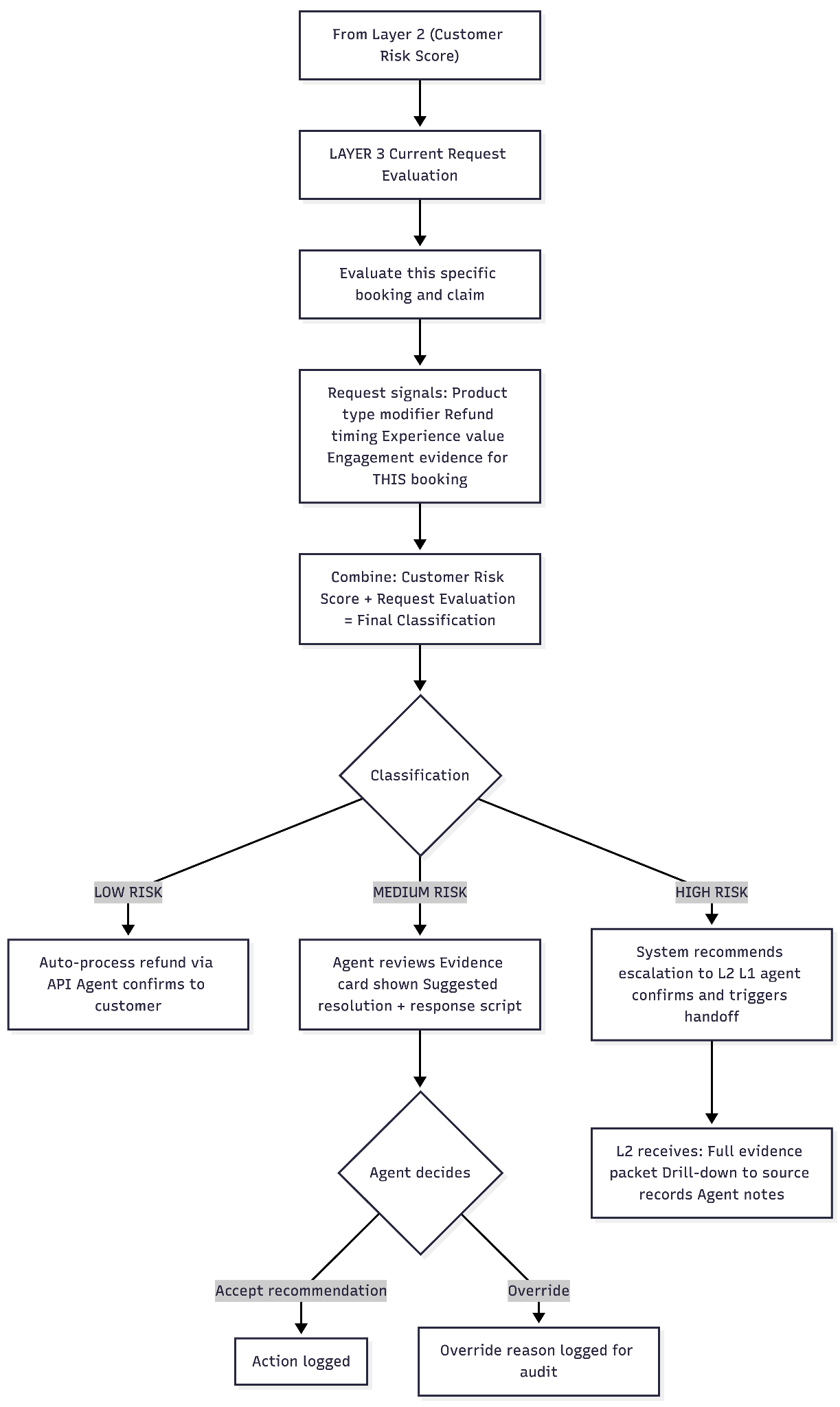
Layer 3 — Current request evaluation
Layer 2 tells us who this customer is. Layer 3 tells us what they are asking for. The two are kept intentionally separate because a high-risk customer making a reasonable request and a low-risk customer making an unreasonable request require different handling.
This layer evaluates: the product type (non-cancelable, high-value requests carry more weight because that is where abuse actually costs money); the timing of this specific request relative to the experience; engagement evidence for this specific booking; and the claim itself versus available evidence. Auto-approval only occurs when the customer profile is clean and the request itself is reasonable. Neither dimension alone is sufficient.
Layers 4–5 — Classification, handoff, and live case management
The combined output of Layers 2 and 3 produces a classification. Three paths:
- Low risk — auto-process (target 70–75%). The system processes the refund via the payment API. The agent confirms the outcome to the customer. Minimal agent time — the bottleneck is only the human conversation, not system processing.
- Medium risk — agent decides with support (target 20–25%). The agent sees an evidence card with the specific flags in plain language (not raw scores), a suggested resolution path, and an LLM-generated response script grounded in the evidence and policy training documentation. The agent makes the call.
- High risk — escalate to L2 (target 5–8%). The system recommends escalation and surfaces the escalation path as the primary option. The L1 agent initiates the handoff — it is not automatic. This design reflects what L1 is realistically authorised to do. L2 receives the full evidence packet: risk profile, current request context, specific flags that triggered escalation, and L1's interaction notes. Every flag is traceable to its source.
After the initial assessment, the system remains active throughout the conversation. If the situation evolves — the customer becomes aggressive, threatens a chargeback, provides new information — the agent relays that context. The system combines it with the existing evidence and relevant policy sections (escalation criteria, aggression handling guidelines, L1 authority boundaries) and returns updated guidance. The deterministic classification does not change; what changes is the recommended action path.
What agents see
L1 — customer service agent
The moment a customer reaches out, the system pulls their risk profile and surfaces a compact strip at the top of the interface: tenure, booking count, refund count, refund rate, and a colour-coded disposition (green / yellow / red). This loads while the agent is greeting the customer — zero additional processing time.
Once the agent identifies the specific order, the system runs all four layers and returns: a risk level, the top contributing factors expressed in plain language ("Customer has claimed no-show 3 times in the past 4 months" not a raw score of 74), a recommended action, and an LLM-generated response script. The script is grounded in both the specific evidence surfaced and the policy training documentation — the agent receives language that is firm but not accusatory, calibrated to this exact case.
L1 authority boundaries are explicit in the interface. What L1 can approve without escalation: any low-risk full refund; any policy-compliant cancellation regardless of risk profile; partial refunds at the applicable policy rate; goodwill coupons up to 25% of booking value for medium-risk cases. What requires L2: non-cancelable product refunds beyond the coupon threshold; overriding a high-risk classification to approve; any refund exceeding $200 on a non-cancelable product; formal denials (L1 does not deny — they escalate). When the recommended action exceeds L1's authority, the system surfaces the escalation path as the primary option.
L2 — floor manager
An escalation queue sorted by risk score. Each case comes with the complete risk profile, the specific flags that triggered escalation, full drill-down capability from any flag to its source data, the L1 agent's notes, and an LLM-synthesised narrative summary. Instead of reading through 15 data fields, the floor manager receives something like: "Customer with 14 refunds across 22 bookings in the past year. Current request is a no-show claim for a high-value experience (top 8th percentile). QR scan confirms attendance. This is the third no-show claim in 2 months; the previous two were approved before the system was in place." Every L2 decision is logged with reasoning.
Reporting
The operations and risk team sees aggregate dashboards across all processed records: classification distribution, auto-approval rates, override rates by agent, flag type trends by experience and supplier, and — most importantly — cases where the system recommended escalation or denial but the agent approved anyway. Those overrides are the highest-priority cases for retrospective audit, because they represent potential abuse that was approved despite the system catching it.
LLM integration
The deterministic engine without the LLM gives scoring but leaves agents to figure out what to say. The LLM without the deterministic engine gives polished language with no objective decision support. The system ships as one product because neither layer works well without the other.
The LLM does not sit in the decision path. It does not score, classify, or route. It handles four specific jobs — and the model choice for each is deliberate.
| Job | Model | Why | Cost/call |
|---|---|---|---|
| Response script generation | Claude Haiku 4.5 | Short-form generation, fast throughput. Does not require reasoning depth. Receives evidence card + policy docs as context. | ~$0.00125 |
| Agent note extraction | Claude Haiku 4.5 | Classification and extraction on short inputs (50–200 words). Haiku handles this well. | ~$0.00125 |
| Evidence summarization for L2 | Claude Sonnet 4.5 | Synthesis and reasoning across multiple evidence types to produce a coherent narrative. A judgment task, not just generation. Haiku does not have the reasoning quality needed here. | ~$0.0105 |
| Agent contextual guidance | Claude Haiku 4.5 | Short, policy-grounded response to situational update. Similar in nature to script generation. | ~$0.00125 |
Why not open-source at launch: API-based models require no GPU infrastructure, no model hosting, no inference optimisation. For a new system being deployed for the first time, reducing operational surface area is the right priority. The migration path is clear and documented: once inference volume scales or cost sensitivity increases, Haiku tasks (response scripts, note extraction, contextual guidance) can move to a self-hosted smaller model such as Mistral 7B or Llama 4 Scout quantised to 4-bit. The Sonnet task (evidence summarisation) should remain on a capable model given the reasoning requirement.
In the prototype, Llama 3.1 8B via Groq handles Haiku tasks and Llama 3.3 70B via Groq handles evidence summarisation. Both run on Groq's free tier. The architectural patterns — deterministic-first, LLM as communication layer, evidence-driven UI — are identical to production. Only the infrastructure is simplified.
Edge cases
- Vendor-side failure causing mass refunds. Layer 0 catches this — the experience-level anomaly check routes all related requests to the Vendor Investigation Queue before individual scoring begins. The structured data also feeds into supplier-facing reports.
- Loyal customer with a sudden spike. A 3-year customer with 80 completed bookings who files 3 refund requests in one month. The tenure modifier reduces their risk contribution, but the system surfaces the unusual pattern to the agent as an observation — not a recommendation for denial. The agent uses judgment.
- No QR data available. The system proceeds with the remaining five signals. The evidence card explicitly notes "vendor check-in data unavailable" so the agent knows the basis is thinner. In ambiguous cases, the absence of QR data tips the classification toward agent review rather than auto-processing.
- First-time customer, first refund. Very little to score on. The default treatment is legitimate unless the specific request triggers a hard-rule flag (QR contradiction is the main one that applies without history). Creating friction for new customers based on absence of data would damage acquisition.
- Retrospective flag after approval. The risk profile is updated. No clawback mechanism — that is out of scope. The updated profile surfaces the next time the customer interacts. The retrospective data also feeds into the scoring calibration set.
- False denial recovery. The system never auto-denies, so this should be rare. When it occurs, the override log and decision audit trail provide the full basis for the reversal. Every denial decision is traceable to the specific data that informed it.
- Policy-compliant request from a flagged customer. Handled explicitly in Layer 1. The refund is processed per policy. The interaction is logged and the profile updated. No friction is added to compliant requests regardless of risk profile — this is a contractual obligation, not a discretionary decision.
Results and targets
The 88% reduction in agent hours comes from the auto-approval math: 3,625 low-risk cases at 1 minute each (3,625 min) + 1,000 medium-risk cases at 3 minutes each (3,000 min) + 375 escalated cases at 7 minutes each (2,625 min) = 9,250 total minutes per month, or ~154 agent hours. Median is the right metric over average here — outlier escalations would distort the average and obscure whether the system is working for the majority of interactions.
The residual 2% fraud target is an honest acknowledgment, not a failure. The system catches obvious cases (QR contradiction, retrospective flags) and pattern-based cases (risk scoring). The remaining 2% are sophisticated or first-time abusers that a deterministic rules-based system cannot reliably detect without labeled training data. Calling this out explicitly is part of the design — the system should not be oversold on what it can do in its first version.
Future path
After 3–6 months of operation, every system decision generates labeled data: confirmed-legitimate approvals (customer never returns with further suspicious behavior), confirmed-fraudulent denials, agent overrides with their outcomes. This creates the foundation for training a supervised model — logistic regression or a lightweight gradient-boosted model — that can learn patterns the deterministic rules miss.
The model would not replace the rules engine. It would sit alongside it as an additional scoring signal, with the explainability requirement still enforced. Interpretable models only — no black-box classifiers without justification for the classification.
Why not ML at launch: there is no labeled fraud dataset. Only sparse retrospective flags, discovered inconsistently. The rules-based system generates clean, structured, decision-level labels at scale. That is the prerequisite for any meaningful model training, and the system is designed from day one to produce it.
What I learned
The most useful reframe I found early: the problem was never that agents were approving too much. It was that they had no information basis for anything else. Once I saw it as an information asymmetry problem rather than a compliance problem, the entire design direction changed. You stop trying to constrain agent behavior and start trying to give agents something objective to stand on. That reframe — from "agents are wrong" to "the system is wrong" — is where the real work began.
I also learned that building for a human in the loop is genuinely harder than building without one. The technical layers were tractable. The harder problem was making the system actually usable by an agent under conversational pressure — someone who has a customer on the line, has maybe 90 seconds to decide, and needs the system to be both fast and trustworthy. Every choice in the evidence card (plain language, not raw scores), the LLM-generated response script, the explicit L1 authority boundaries — all of it exists to reduce the cognitive load at the moment of decision, not to make the system technically cleaner. The constraints I initially treated as problems — no labeled fraud data, inconsistent QR coverage, policy variation by product — turned out to be the right design inputs. They forced architectural choices (deterministic-first, QR as bonus not requirement, the policy gate as Layer 1) that I would not have arrived at otherwise.
Try the live prototype† Horizon is a pseudonym. The operational challenge described — refund abuse at scale in booking environments — is real and common across experiences marketplaces, travel aggregators, distribution platforms, and any business where high-volume third-party fulfilment creates information asymmetry between the customer and the agent handling their claim.